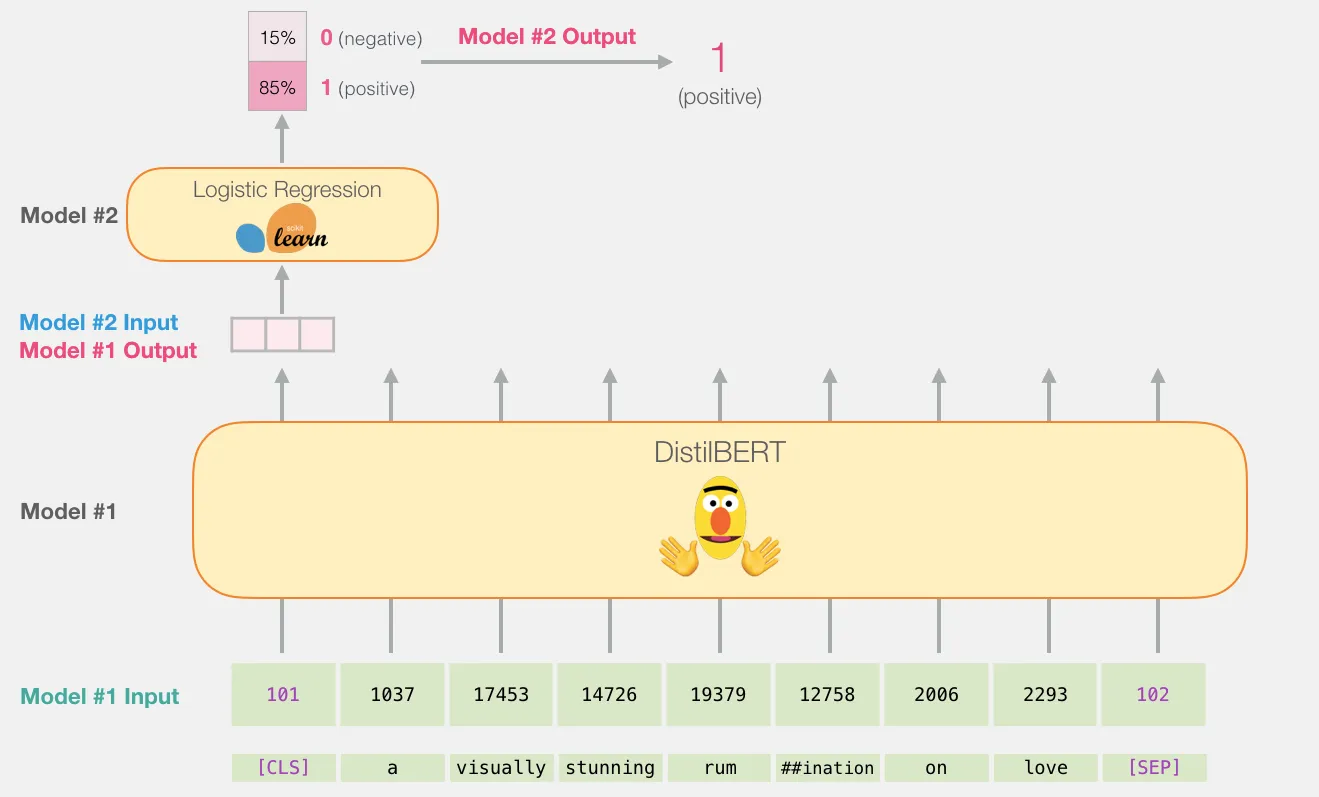
Phrase Retrieval in ODQA Error propagation: 5-10개의 문서만 reader에게 전달됨retrieval에 의존도가 높아짐Query-dependent encoding: query에 따라 정답이 되는 answer span에 대한 encoding이 달라짐query와 context를 concate해서 encoding을 하다보니 query가 달라지면 모두 다시 encoding을 해야함 Phrase search (document search) 문서 검색을 하듯이 phrase(절)을 바로 검색할 수는 없을까라는 아이디어에서 나옴Phrase indexing문장에서 각 phrase마다 나누어 key vectors를 생성해둔다면 query vector만 encoding하여서 Nearest..