
데이터 분석 과정
1. 데이터 분석이란 ?
구글 코랩 알아보기
데이터 찾기
2. 데이터 수집하기
파이썬으로 JSON과 XML 데이터 다루기
API 사용하기
웹 스크래핑 하기
뷰티플수프 사용하기
3. 데이터 정제하기
pandas 기반 불필요한 데이터 삭제하기
잘못된 데이터 수정하기
4. 데이터 요약하기
기술통계 구하기
분포 그래프 그리기
5. 데이터 시각화하기
matplotlib으로 그래프 그리기
6. 복잡한 데이터 표현하기
matplotib 고급 기능 배우기
7. 통계적으로 추정하고 머신러닝 예측하기
1강. 데이터 분석이란 ?
데이터 과학 4가지 요소
통계학, 머신러닝, 데이터 분석, 데이터 마이닝
데이터 과학자 '지 리'의 답변
데이터 과학은 데이터 세계와 비즈니스 세계를 잇는 다리입니다. 데이터 과학을 활용해서 소프트웨어나 제품을 개발할 수 있지만 이것이 전부는 아닙니다. 또 데이터 과학이 통계학과 관련이 많다지만 통계학 자체는 아니며, 학술적인 분야 또한 아닙니다. 멋진 그래프를 그리기도 하지만 이것이 데이터 과학의 전부는 아닙니다. 오히려 데이터 과학은 이 모든 것을 포함합니다. 데이터 과학을 하려면 프로그래밍, 통계학, 시각화와 더불어 비즈니스 감각을 갖추어야 합니다.
데이터 분석; 사람의 의사결정을 위한 통찰을 제공
데이터 과학; 통찰보다는 문제를 해결하기 위한 솔루션을 제공
데이터 분석가 = 프로그래밍 기술 + 수학/통계 + 도메인 지식

2강. 데이터 분석으로 비즈니스 문제를 해결하는 방법
CSV 파일 출력하기
with open('.csv', encoding='euc-kr') as f:
print(f.readline()) # 한줄씩 읽기
read_csv()
df = pd.read_csv('.csv', encoding='euc-kr', low_memory=False)
df.head() # 상위 5개 요소만 보여주기
df.to_csv('.csv') # DataFrame 개체를 csv파일로 다시 저장
3강. API를 사용하여 데이터 수집하기

API란 ?
Application Programming Interface
두 프로그램 사이의 대화하는 규칙을 정의
HTTP란 ?
텍스트 기반의 프로토콜
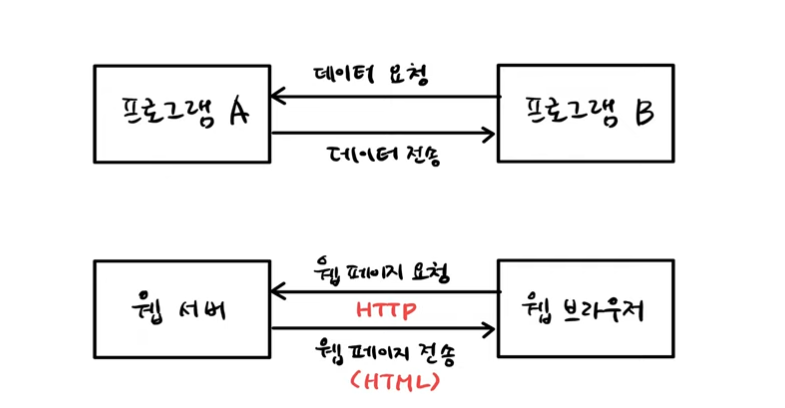
데이터 형식은 CSV, JSON, XML !
JSON

JSON 문자열 다루기

복잡한 JSON 구조

XML

findtext()

복잡한 XML 구조

브라우저에서 URL 호출하기

requests로 URL 호출하기

데이터프레임으로 바꾸기

4강. 웹 스크래핑 사용하기
웹 크롤링

뷰티플수프

find() method
id가 Infoset_specific 속성을 가진 'div' 태그를 찾아줘

find_all() method

웹 스크래핑 주의할 점
- 웹사이트에서 스크래핑을 허락했나요 ? (robots.txt)
- HTML 태그를 특정할 수 있나요 ?
- 페이지가 동적으로 생성되나요 ?
- 디자인이 자주 변경되나요 ?
데이터프레임의 행과 열 선택하기 - 1
.loc()으로 행, 열을 지정할 수 있음

데이터프레임의 행과 열 선택하기 - 2
.loc()으로 행, 열을 지정할 때, slicing 사용할 수 있음

5강. 불필요한 데이터 삭제하기
열 삭제하기

loc method와 boolean 배열

columns에 들어있는 모든 요소에 대해 해당 문자열과 비교하여 True/False 반환

drop() method
axis = 0 : 행 / axis = 1 : 열

dropna() method
null (NaN)값을 가진 행/열을 삭제
dropna()는 하나라도 NaN 값이 있으면 삭제하지만, how='all'은 모든 원소가 NaN일 경우 삭제

행 삭제하기
행의 index를 통해 삭제

[] 연산자와 boolean 배열

duplicated()로 중복된 행 찾기
중복된 행이 두 개 있을 경우
첫 번째 행은 중복되지 않았다(False)를 return하지만, 두 번째 행은 중복되었다(True)를 return

keep=False, first, last ?
keep='first'인 경우, 중복이 있으면 첫 번째 값을 False, 나머지는 True를 반환
keep='last'인 경우, 중복이 있으면 첫 번째 값을 True, 나머지는 False를 반환
keep=False인 경우, 처음이나 끝 값인지 고려안하고 중복이면 무조건 True 반환

Group by()로 그룹별로 모으기
sum()으로 대출건수를 합친 결과를 확인할 수 있음


6강. 잘못된 데이터 수정하기
info() method

isna() method
비어있는 값만 확인가능

NaN
pandas에 NaN이라는 객체가 없기 때문에, np.nan을 입력함

fillna() method
NaN 값을 다른 값으로 손쉽게 바꿀 수 있음
모든 열에서 NaN의 값을 '없음'으로 채움
+ 해당 열에서만 비어있는 값 채우기

replace() method
바꾸는 값이 여러 개일 경우 list/dictionary이렇게 바꾸기
특정 열에 있는 값만 바꾸기 (부가기호의 np.nan을 '없음'으로 바꿈)

정규 표현식
\d: 임의의 한 숫자를 의미 [0-9]와 동일한 표현식
r: 정규 표현식을 의미\d{2}: \d가 2개 있음을 의미


.*: 임의의 문자열의 길이


contains() method

7강. 통계로 요약하기
describe() method - 1

describe() method - 2
30%, 60%, 90%에 있는 데이터 확인
include = 'object'는 문자열 데이터 의미

mean()으로 평균 구하기

median()으로 중앙값 구하기

qunatile()으로 분위수 구하기

var()으로 분산 구하기
분산: 흩어짐의 정도

std()으로 표준편차 구하기
표준편차: 분산에 제곱근을 해주어 값을 조정한 것
pandas와 numpy가 표준편차를 구하는 방법이 다름

mode()로 최빈값 구하기
최빈값: 많이 등장한 값

8강. 분포로 요약하기
matplotlib.pyplot의 scatter()으로 산점도 그리기
alpha: 투명도 조절 (0 ~ 1사이로 지정)


hist()으로 히스토그램 그리기 - 1
히스토그램: 구간으로 나누어 구간 안에 포함된 데이터 개수를 막대 그래프로 그림
histogram_bin_edges()로 구간 값을 정확히 나눌 수 있음
bins: 구간으로 나누는 수


hist()으로 히스토그램 그리기 - 2
정규분포의 데이터를 만들어서 평균과 표준편차 구함
정규분포: 평균을 중심으로 좌우 대칭인 그래프
표준 정규분포: 평균 0 / 표준편차 1
randn(): 랜덤한 실수 생성
ex. np.random.randn(1000): 1000개 데이터 생성
seed(): 유사난수 생성

작은 구간에 있는 도수가 잘 표현이 되지 않을 때, y폭을 조절할 수 있음
plt.yscale('log') log scale로 y축이 바뀜

boxplot()으로 상자 수염 그림 그리기
최솟값, 세개의 사분위수, 최댓값 데이터 요약하는 그래프IQR: 25% 백분위수, 75% 백분위수 사이의 거리상자 수염 그림을 수평으로 그리기: vert=False / vert=True(default)수염 길이 조절: whis=10


14강. 머신러닝으로 예측하기

훈련 데이터 / 테스트 데이터을 모델에 입력하여 모델 훈련 / 검증

선형 회귀 (Linear Regression) - R square

로지스틱 회귀 (Logistic Regression) - binary classification - accuracy

'머신러닝 및 딥러닝 > 데이터 분석' 카테고리의 다른 글
| ColumnTransformer (Encoding) (1) | 2024.05.03 |
|---|---|
| train_test_split의 random_state 의미 (0) | 2024.05.03 |