최근 소개되는 언어 모델들은 긴 컨텍스트 윈도우(Long-Context Window)를 기본으로 지원한다.
이는 언어 모델이 한 번에 많은 양의 데이터를 처리할 수 있음을 의미한다.
Many-Shot In-Context Learning이 가능해지면서 프롬프트 엔지니어링 전략만으로도 언어 모델의 성능을 향상시킬 수 있게 되었다.
과거에는 특정 목적을 달성하기 위해서 사전 훈련된 언어모델에 Fine-tuning 과정이 필요했지만,
이제는 더 적은 데이터로 많은 비용과 시간을 들이지 않고도 성능을 높일 수 있게 되었다.
따라서 이제는 fine-tuning의 필요성에 대한 의문을 제기하기 시작했다.
그렇다고 fine-tuning이 완전히 쓸모 없는 것은 아니다.
최근에는 규모가 큰 사전 훈련 모델의 전체 파라미터를 업데이트 하는 방식(full fine-tuning)이 아니라,
일부 파라미터를 효율적으로 업데이트하는 방식을 연구하고 있다.
따라서, fine-tuning보다 훨씬 더 적은 데이터와 비용으로 안정적인 성능을 낼 수 있다는 것이다.
그렇다면 ICL과 PEFT 중에 어떤 것이 더 좋을까 ?
질문에 답하기 앞서, fine-tuning과 ICL이 어떤 발전 과정을 거쳐왔는지 이해해야 한다.
Fine-tuning: 언어 모델의 능력을 빌려오자
2018년, BERT는 당시 기준으로 뛰어난 자연어 이해 능력을 가지고 있었다.
일반적인 언어 특성을 이해하고 있는 BERT는 다양한 도메인에서 두루 활용이 가능했다.
하지만 BERT를 특정한 목적에 맞게 활용하기 위해서는 추가적인 학습이 필요하다.
그 과정은 다음과 같다.
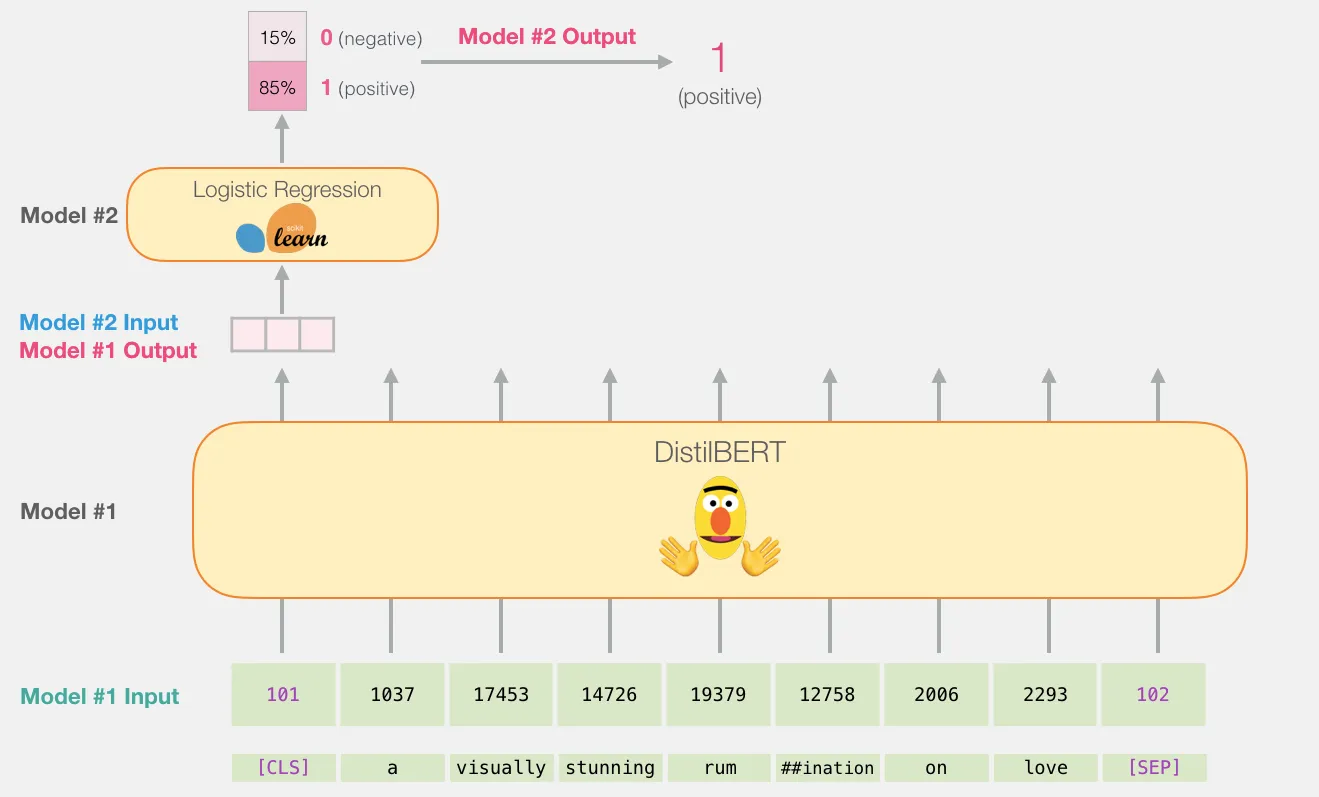
BERT 구조를 유지한 채 마지막 단계에 텍스트 분류가 가능한 레이어를 추가하고,
텍스트 분류를 위한 학습 데이터를 추가로 훈련시키면 된다.
예를 들어, 어떤 텍스트에 나타난 긍/부정 감정을 분석하고 싶다면
마지막 레이어의 출력값이 2개가 되도록 설정하면 된다.
이 과정에서 사전 학습된 모델의 파라미터 값들은 약간씩 조정된다.
감정 분류 작업을 수행하기 위해, 새로운 학습 과정을 거치며 파라미터를 업데이트 하기 때문이다.
이것을 사전 학습된 모델을 기반으로 파라미터를 미세(fine)하게 조정(tuning)하는 fine-tuning이라고 한다.참고로 이렇게 축적된 지식 정보를 활용하여 새로운 목적으로 학습하는 과정을 전이학습(transfer learning)이라고 한다.
Fine-tuning만 하면 누구나 언어 모델을 사용할 수 있다는 점이 매력적이다.
하지만 아무리 적은 데이터셋으로 학습이 가능하다고 하더라도, 이는 사전 학습 데이터셋에 비해 적은 규모를 의미한다.
당시에는 수 천개에서 수 백만개의 데이터가 있어야 Fine-tuning이 가능했다.
그리고 언어 모델을 학습시키기 위해서는 수 백 - 수 천 만원에 달하는 GPU 성능이 필요하다.
이런 점들을 고려하면, 여전히 개인 수준에서 Fine-tuning 학습에 드는 비용을 감당하기는 쉽지 않다.
어떤 글에 표현된 감정이 긍정인지 부정인지 분류하는 간단한 과정이라고 하더라도,해당 데이터셋을 수집하고 훈련시키는데 만만치 않은 비용을 감당해야 한다는 것이다.
In-Context Learning: 이제는 Fine-tuning 필요 없다
언어 모델이 발전하면서 LLM의 시대가 열렸다.GPT-3가 그 서막을 열었다고 할 수 있다.
GPT-3를 처음 소개한 논문의 원제는 <Language Models are Few-Shot Learners>이다.
해당 논문에서 본격적으로 in-context learning 개념이 알려지기 시작했다.
ICL은 컨텍스트 안에 주어진 여러 샷들을 학습하여, 답변의 패턴을 이해하는 과정이다.
내가 원하는 답을 얻기 위한 문제에 대해 몇 가지 예제들을 만들어 두고, 이를 언어 모델에게 프롬프트로 입력한다.
(우리가 쉽게 이해할 수 있는 자연어 형태로 말이다.)
ICL은 예제의 개수에 따라 zero-shot / one-shot / few-shot 등으로 구분할 수 있다.
Shot이란 모델에게 주어진 예제, 즉 (입력-target) 쌍을 의미한다.
즉, 언어 모델에게 적은 예제를 제공해도 이를 학습해서 적절한 답변을 낼 수 있다는 뜻이다.

이렇게 몇 개의 예제를 보여주고, 다음에 무엇이 올지 예측하도록 문제를 제공하며 원하는 답변을 얻을 수 있다.
ICL이 Fine-tuning 과정에 비해 훨씬 간편하다.
모델의 일부를 수정하지 않아도 되고, 훨씬 적은 예제 데이터만 있어도 원하는 결과를 얻을 수 있다.
하지만, 이런 장점들에도 불구하고 몇 가지 치명적인 단점이 존재한다.
우선, 모델이 추론(Inference)을 할 때마다 많은 계산 비용이 든다.
학습이 완료된 모델로 새로운 입력값에 대해 예측하는 과정을 추론이라고 한다.
학습 과정에서도 연산이 필요한 것처럼 입력된 값을 처리하는 추론 과정에서도 비용이 발생한다.
ICL의 특성상 많은 예제들을 입력해야 성능이 개선되는데,
입력 프롬프트의 길이가 길어지면 길어질수록 계산 비용은 높아질 수 밖에 없다.
한 번 fine-tuning한 모델의 경우, 입력 프롬프트에 예제를 입력할 필요가 없기 때문에,
학습 과정에서는 계산 비용이 많이 들더라도 추론 과정에서는 비용을 절약할 수 있다.
또한 프롬프트의 형식에 따라 성능에 영향을 미친다는 점도 ICL의 단점으로 꼽힌다.
결국 예제를 입력하는 방식 또한 프롬프트 엔지니어링의 일종인데,
어떻게 입력 포맷을 설정하느냐에 따라 성능에 차이가 난다는 점에서 일관성이 떨어질 수 있다.
심지어 동일한 예제를 활용하더라도, 예제의 순서를 바꾸는 것만으로도 성능에 영향을 미치기도 한다.
이런 점을 고려했을때, fine-tuning의 성능이 더욱 안정되고 ICL에 비해 높은 정확도를 보이는 경향이 있다.

그리고 부정확한 레이블을 제공하더라도 제대로 된 답을 내기도 한다는 연구도 발표됐습니다.
<Rethinking the Role of Demonstrations: What Makes In-Context Learning Work ?> (Min et al., 2022)
이런 ICL의 문제점들이 지적되면서, 정말로 모델이 예제를 학습하는 것이 맞냐는 의문이 제기됩니다.

PEFT: 그럼 Fine-tuning을 효율적으로 ?
Fine-tuning의 비효율성은 모델 전체 파라미터를 조정하는 과정에서 기인합니다.
특히나 LLM이 등장하면서 전체 파라미터를 업데이트 하는 것은 더욱 어려워졌다.
따라서 효율적으로 Fine-tuning하는 방법에 대해서도 많은 연구가 이루어졌다.
이를 PEFT(Parameter Efficient Fine-tuning)이라고 한다.
PEFT의 핵심은 파라미터 전체가 아닌 일부만 효율적으로 조정하여,
적은 연산 비용으로도 full fine-tuning한 것과 유사한 성능을 갖도록 만드는 것이다.
1. Adapter
PEFT에는 다양한 방법이 있지만, 대표적인 방식 중 하나가 Adapter를 추가하는 것이다.
BERT 모델의 경우, 마지막 단계에 분류를 위한 레이어를 추가하는데, Adapter를 추가하는 과정도 이와 아이디어가 유사하다.
가장 큰 차이점이 있다면, 사전 학습된 모델은 업데이트 하지 않고 (얼리고)
추가된 Adapter의 파라미터만 업데이트하는 것이다.

일반적으로 Adapeter는 위의 그림처럼 트랜스포머 블록 사이에 추가된다.
Adapter 개념이 처음 소개된 <Parameter-Efficient Transfer Learning for NLP> 논문에서
Adapter로 추가된 파라미터는 전체의 약 3.6%에 불과하다.
이만큼 적은 양의 파라미터를 업데이트하고도 성능 차이는 0.4% 이내이다.근소한 성능 차이를 희생하는 대신,
막대한 학습 비용을 절약할 수 있다는 것이다.
이런 아이디어는 다양한 PEFT 방법론 연구에 크게 기여했다.
2. Prefix Tuning
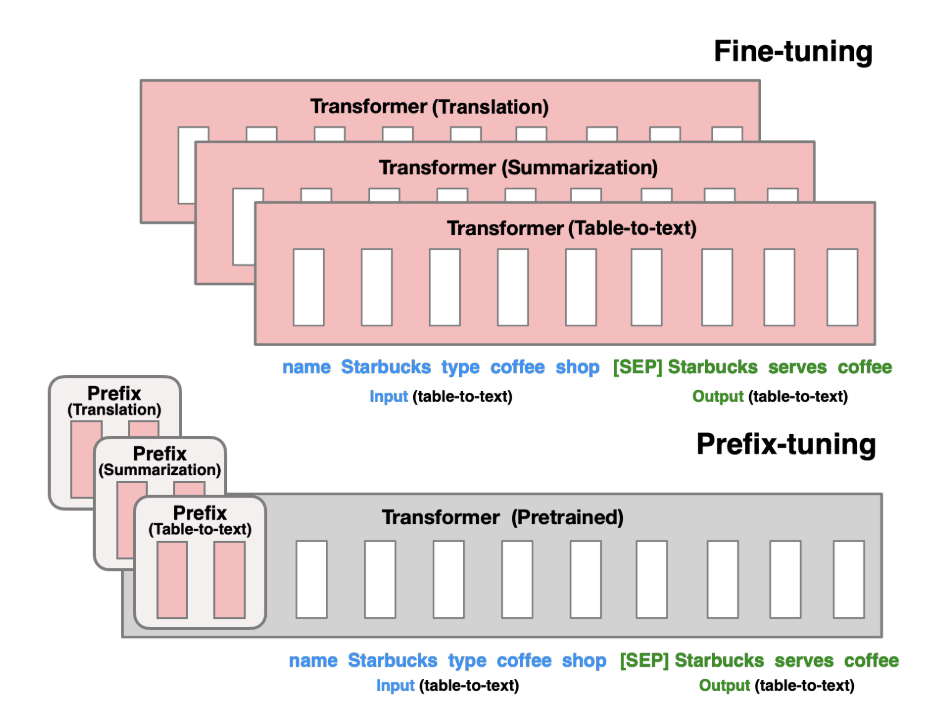
또 다른 방법으로는 Prefix Tuning이 있다.
<Prefix-Tuning: Optimizing Continuous Prompts for Generation> (Xiang Lisa Li., 2021)
Prefix라는 단어에서 알 수 있듯이, 사전 학습된 파라미터의 앞단에 추가하는 방법이다.
기존 fine-tuning 방식은 하위 태스크의 종류에 따라 각 모델을 따로 학습시켜야 했기 때문에 유연성(flexibility)이 떨어졌다.
하지만 prefix tuning으로 다양한 태스크에 학습된 여러 개의 Prefix 블록을 활용한다면,
파라미터 저장 공간도 절약하면서 유연성을 극대화할 수 있다.
3. Reparametrization
최근에는 LoRA 모델로 대표되는 Reparametrized Fine-tuning이 주목 받고 있다.
<LoRA: Low-Rank Adaptation of Large Language Models> (Edward J. Hu., 2021)
일부 파라미터만 학습하면서 동시에 다양한 태스크에 유연하게 활용하기 좋고, 성능까지 뛰어나기 때문이다.
보통 사전학습 모델을 미세 조정해서 downstream task를 해결하는데 필요한 정보는 일부이다.
기존 연구들을 통해서 필요한 정보는 Intrinsic dimension에 있을 것이라고 판단했다.
이러한 Intrinsic dimension을 찾기 위해 'Low-Rank space'로 변환하는 방식을 사용하면,
더 적은 파라미터로도 같은 성능을 낼 수 있을 것이라고 판단했다.
(Rank: 어떤 matrix에서 의미가 있는 기준들 = column vector의 개수
Low-Rank: Rank 중에 의미있는 적은 정보)
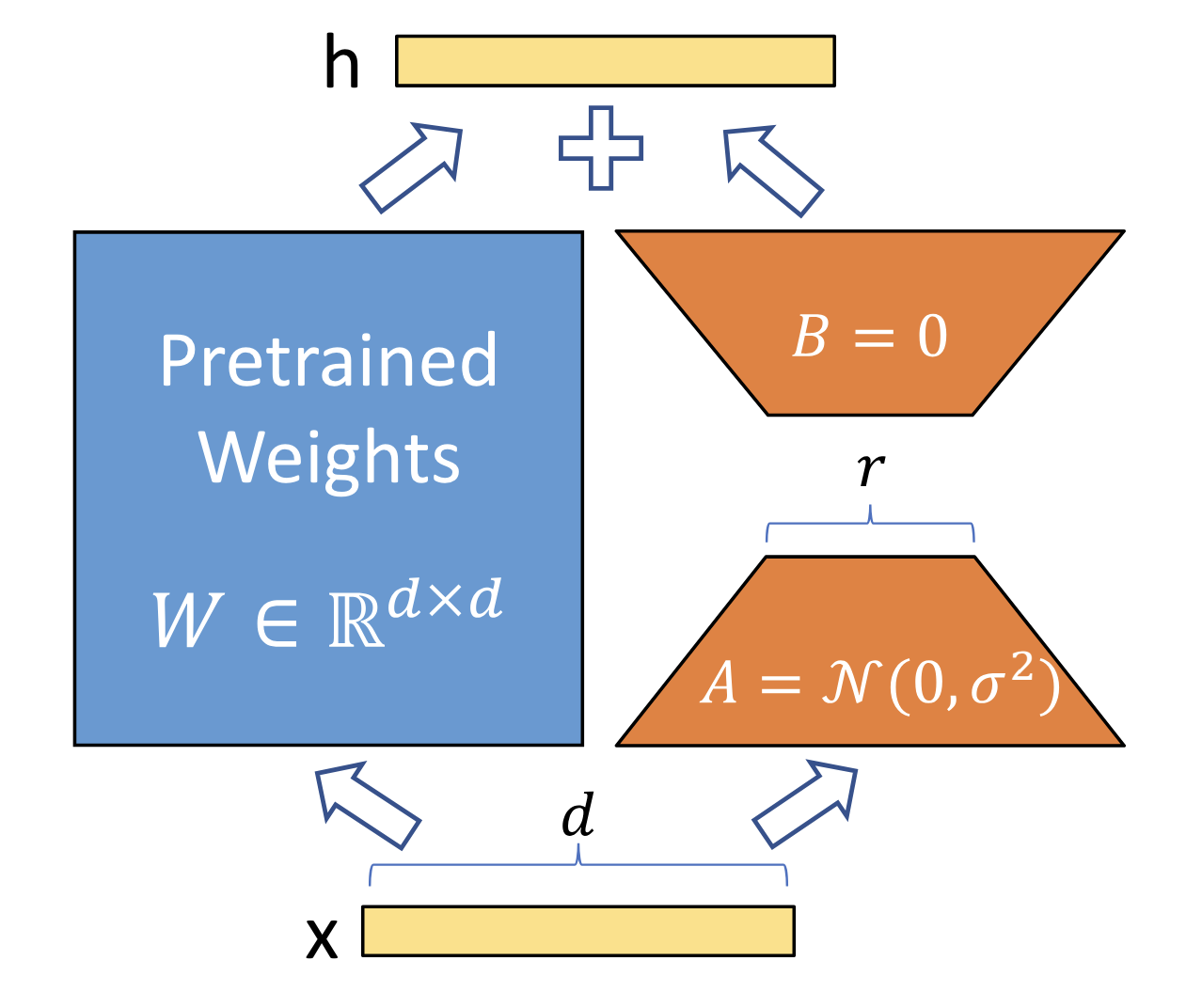
해당 방법은 입력 단계나 중간 단계에 Adapter 블록을 삽입하는 것이 아니라,
낮은 차원의 행렬을 업데이트한 뒤, 사전 학습된 파라미터 값에 더하는 방식이다.
이 방식 역시 다른 태스크로 전환이 유연하게 이뤄질 수 있는데,
특정 LoRA 모듈의 가중치를 다시 빼고, 새롭게 전환할 태스크의 가중치를 더하기만 하면 된다.
이 밖에도 몇 가지 장점이 있다.
다른 방법론은 기존 모델 사이에 레이어를 추가하는 만큼, 추론 시에 약간의 시간 소요가 더 된다.
그러나 LoRA는 추론 시 기존 파라미터에 병합되기 때문에 추론 속도를 유지할 수 있다.
게다가 모델의 입력과 출력 등 다른 단계와 독립적이기 때문에, 원한다면 prefix tuning 등의 다른 방법론과도 결합이 가능하다.
이런 장점 때문에 최근 LLM 모델을 fine-tuning할 때 LoRA를 기반으로 한 방법론이 자주 활용된다.
(작년에는 LoRA에서 양자화까지 반영한 QLoRA와 관련된 연구들이 많이 제안되었다.
sLM이 부상하면서, 개인 컴퓨터 환경에서 언어 모델을 fine-tuning하도록 만들었기 때문이다.)
하지만, sLM에서도 long-context를 지원하면서, many-shot ICL이 가능해지면서 많은 이야기가 나오고 있는 중이다.
# 해당 글은 deep daiv의 내용을 요약한 것입니다.
'머신러닝 및 딥러닝 > 자연어처리' 카테고리의 다른 글
| 오토인코더(Auto Encoder) ・ Variational 오토인코더 (0) | 2024.06.27 |
|---|---|
| 난수 ・ random seed (0) | 2024.05.13 |
| Batch size와 Learning rate의 상관 관계 (0) | 2023.11.18 |
| Transfer Learning & Fine-tuning (2) | 2023.11.18 |
| Vision-Language Model | self-attention vs cross-attention (0) | 2023.08.01 |